Grape to Glass: Apache Pinot™ 1.0 Uncorked

Announcement
Today marks a momentous occasion as we celebrate the graduation of Apache Pinot™ to 1.0. This achievement has been years in the making and represents not only a significant milestone but also a promising glimpse into the future. I want to express my heartfelt gratitude to all those who have played a role in the success of Apache Pinot.
As we stand here today, it's essential to reflect on our journey, appreciate the distance we've covered, and envision the path that lies ahead.
This milestone also gives us a moment to reflect on the project's origins and reflect on the journey thus far and accomplishments made. Let’s look back at the journey.

The Journey to Pinot 1.0
Pinot's journey started in 2013 at LinkedIn and the project has continued to evolve, now with a vibrant community and used by Fortune 5000 companies. It was first announced to the world in 2014 and open sourced in 2015.

Figure 2: Illustrates the timeline of Apache Pinot Evolution. Pinot’s journey began in 2013, quickly became the backbone of LinkedIn's analytics infrastructure in 2014 - powering systems like Statserver and handling real-time analytics at scale. In 2017, Uber recognized Pinot's capabilities and adopted it for their real-time analytics needs. The project entered into incubation phase in 2019 expanding the adoption into new industries which brought on new features. Pinot soon became a tool that could work for all industries and companies of all sizes and subsequently led to 170x growth in companies within the community as of 2023.
Video: Tim Berglund (VP Developer Relations, StarTree) unpacks the Apache Pinot 1.0 release.
LinkedIn has always been a special place, and what makes it truly fascinating is its propensity to initiate groundbreaking infrastructure projects. This innovative drive has resulted in projects like Pinot, Kafka, Helix, Espresso, Databus, Datahub, Gobblin, and Venice, reshaping how data and systems are managed and harnessed. These projects have not only addressed specific technical challenges but also opened doors to new possibilities, reimagining how data and systems can be managed and leveraged.

Figure 3: Illustrates LinkedIn Data Infrastructure a simplified version
While many companies may attempt to scale existing solutions when faced with increased demands, LinkedIn dared to innovate and develop entirely new systems to address these challenges. For example, traditional messaging systems were not designed to handle scalability and were typically designed as single-node systems. When subjected to 100 or 1,000 times more data, these systems just broke. LinkedIn realized that a system capable of accommodating a 1,000x growth in digitized information was necessary. This prompted the birth of Kafka, as there was no existing infrastructure that adequately met LinkedIn’s needs.
Similarly, in the realm of analytical systems, LinkedIn needed a system capable of ingesting billions of events daily, critical for user-facing products like "Who Viewed My Profile?” that demanded serving 1,000’s of queries per second in real-time with low response times. Yet there were no off-the-shelf options that met these specific requirements, including predictable low latency, real-time data freshness, fault tolerance, and scalability. As a result LinkedIn developed Pinot, a real-time analytics database that not only reduced query costs but also delivered lightning-fast responses.
Pinot became an Apache Software Foundation incubator project in 2018, and graduated to a top-level project in 2021, solidifying its status. By then, Pinot had proven its versatility, finding a home at industry players like Uber. Stripe, Walmart, and Target. It also brought together many of the major leaders of the project, who founded StarTree to shepard Pinot’s growth and adoption. Throughout this journey, a vibrant community of contributors enriched Pinot's capabilities and impact, the growth in the community raised from 100 to 4,000 members and from LinkedIn and Uber to 1,000+ organizations across various industries such as Retail, Food/Logistics, FinTech/Banking, AdTech, Cloud Native/SaaS.

Figure 4: Illustrates the growth in the adoption of Pinot across LinkedIn, Uber early on and further expanding to 1000+ organizations in the community across various industries
This journey underscores the transformative power of open-source innovation, where a solution born out of necessity can go on to revolutionize how data analytics is conducted across diverse industries and organizations. Apache Pinot's future promises even more exciting milestones as it continues to evolve and meet the evolving needs of the data analytics landscape.
The Vibrant Pinot Community
In the last 5 years, we have seen the number of companies getting involved with Apache Pinot increase from 6 to 1000+, a 40x increase in the number of slack members, and a 20x increase in the number of Docker image downloads.

Figure 5: Illustrates the Pinot community growth

Figure 6: Word cloud demonstrating the contributions and engagement of all Pinot Committers in the community
If you, too, would like to join our community, you can join our Slack channel or visit the Apache Pinot community web page.
How the Pinot Project Started and Where It's Heading
In Pinot, we embrace the principle of "Think Big, Start Small," coupled with a commitment to learning and iterating rapidly. When we embarked on the Pinot Project, we were tempted to tackle the entire analytics landscape and broke it down into two pivotal axes: Batch vs. Real-time and Internal users vs. External Users.

Figure 7: Analytics landscape into two pivotal axes: Batch vs. Real-time and Internal users vs. External Users.
This gave us 4 quadrants, each unique in terms of the expectations of freshness, latency, throughput and query flexibility. While analytics lacks an equivalent to the CAP theorem, achieving all these properties in one system is nearly impossible.

Figure 8: Illustrates 4 Quadrants across analytics landscape and critical properties that are important for analytical databases. Freshness, Low Latency, High Throughput and Query Flexibility
Data warehouses and data lake systems already existed to focus on internal users and batch analytics. Our focus honed in on the most challenging yet valuable quadrant – real-time data and external users – a segment we refer to as user-facing analytics. This pursuit prompted us to question conventional assumptions in analytical database theory. While many databases emphasized columnar compression and scan speed enhancement, we charted a different course, elevating indexing as a primary focus. Our initial bet paid off substantially, as we began serving hundreds of thousands of queries per second. Our design choices made it very easy for us to venture into the neighboring quadrants - external analytics on batch data, which still demands high throughput low latency, and internal analytics on real-time data, which demands strict data freshness.
Our objective was to solve freshness and query latency at high throughput, essentially combining OLAP workload capabilities with OLTP scale.
Now, having addressed the challenges of latency, throughput, and freshness, we initiated phase two of our journey — tackling the query flexibility challenge.

Figure 9: 2-phased Pinot Journey addressing the challenges of latency, throughput, and freshness and now tackling query flexibility
While building a system for real-time high concurrency low latency workloads, we had to make trade-offs, particularly in query flexibility. We had implemented a limited subset of SQL functionalities, those that are typically seen in OLAP workloads – filter, aggregation, projection, and group by – omitting features like join and window functions. We also observed that Pinot had accrued significant technical debt.
The project had become tightly coupled with technologies like Kafka, Avro, and Spark, which presented challenges in making substantial codebase changes. Additionally, adding more indexing techniques, storage schemes, etc. required invasive changes to the codebase that required massive lift in building, testing and releasing new versions. We were also missing certain capabilities such as the ability to mutate rows or insert data via write APIs, functionality which are crucial in providing full query flexibility support.
Many distributed projects often halt innovation due to fear of making significant codebase alterations. Here, the Pinot community stands apart and collectively undertook a monumental six-month project to modularize the codebase, breaking it into pluggable SPI modules. Although this endeavor was arduous, it allowed the community to contribute numerous plugins without disrupting the core architecture.
Now looking back, I am glad we undertook this as Pinot now supports a multitude of streaming (Kafka, Kinesis, Pubsub, Pulsar, Redpanda) and batch sources (HDFS, ADLS, S3, GC), diverse data formats (JSON, AVRO, CSV, protobuf), as well as multiple indexes (sorted, inverted, timestamp, range, bloomfilter, geospatial, star-tree, and text).
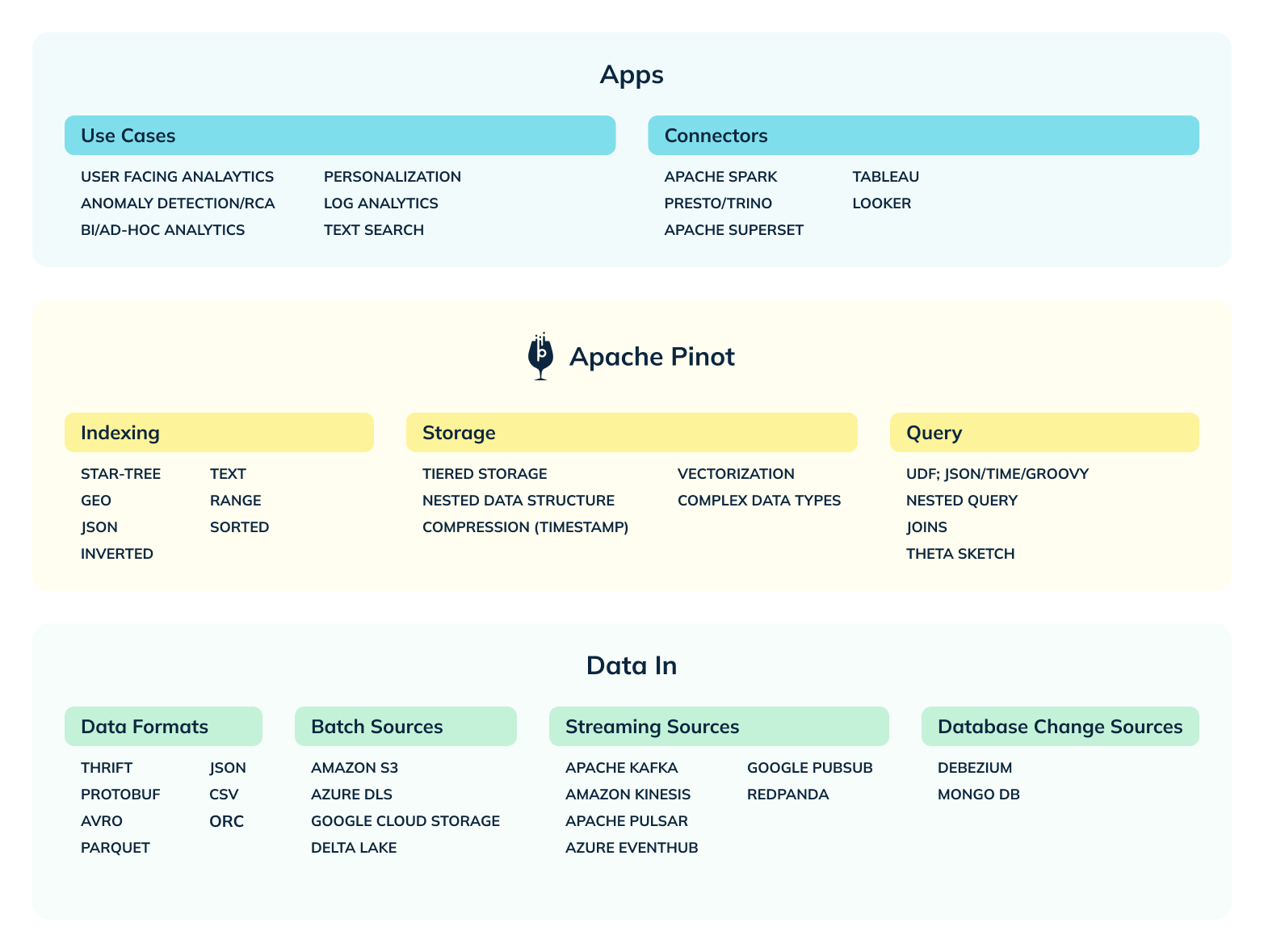
Figure 10: Illustrates the coverage of Pinot
With Apache Pinot 1.0 release, excited to share many new features to support query-time native JOINs, upsert capabilities (supporting deletes, compaction), null value support in queries, support for SPI-based pluggable indexes, and improvements to the Spark 3 connector.
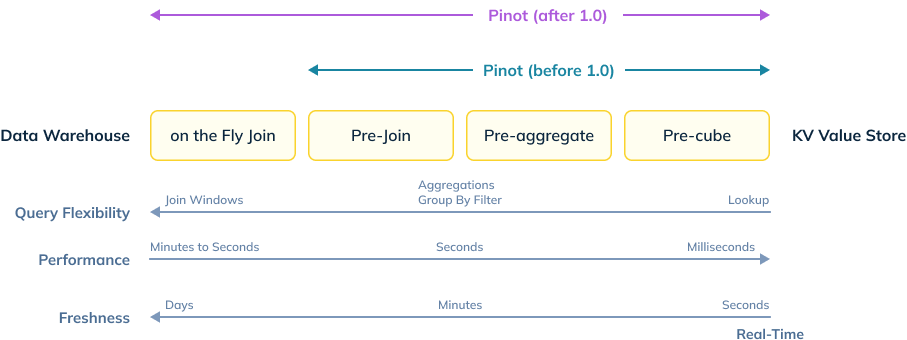
Figure 11: Illustrates the coverage of Pinot before 1.0 and after 1.0 across Query Flexibility, Performance and Freshness
What's Next?
As we reflect on Apache Pinot's remarkable journey, it's evident that innovation, collaboration, and the willingness to tackle arduous challenges have been the cornerstones of our success. From its inception at LinkedIn to becoming an industry-standard real-time analytics database, Pinot has continuously evolved to meet the ever-growing demands of modern data analytics.
Looking ahead, our commitment to excellence remains unwavering. With Pinot 1.0 as a solid foundation, we are embarking on a new phase that includes achieving full SQL support, encompassing features like Window Functions, Match Recognize, Unnest, Materialized Views, and more. We're also enhancing compatibility by making Pinot PostgreSQL API compatible (instead of building an ODBC driver), enabling seamless integration for BI tools with existing PostgreSQL drivers to connect with Pinot. Furthermore, we're broadening our scope to cater to various use cases, including Vector support, handling Log Metrics and Traces.
On log metrics, we are excited to see the work underway with the compressed log processor (CLP). Uber recently published how it dramatically reduced its logging costs using CLP. CLP is a tool capable of losslessly compressing text logs and searching them without decompression. Uber achieved a 169x compression ratio on their log data, saving storage, memory, and disk/network bandwidth.
As we embrace the future, we invite you to join our Slack community on this exciting journey of redefining real-time data analytics. Together, we'll continue to push boundaries, break new ground, and unlock the full potential of real-time data for businesses worldwide. Thank you for being part of the Apache Pinot story.
Cheers to the community for getting us here! Can't wait to see what we do next.
We extend our heartfelt gratitude to our vibrant community, contributors, and users who have been instrumental in shaping Pinot into what it is today. Your passion and dedication drive our continuous innovation and growth.
Download page: https://pinot.apache.org/download/
Getting started: https://docs.pinot.apache.org/getting-started
Join our Slack channel: https://communityinviter.com/apps/apache-pinot/apache-pinot
See our upcoming events: https://www.meetup.com/apache-pinot
Follow us on Twitter: https://twitter.com/startreedata
Subscribe to our YouTube channel: https://www.youtube.com/startreedata
Apache Pinot
Community Newsletter



