Highlighting Innovation in Apache Pinot 1.2

We’re excited to celebrate the minor release of Apache Pinot 1.2.0! It brings a wealth of enhancements, stability enhancements and optimizations that significantly refine the capabilities of Pinot for real-time analytics.
Apache Pinot is the open source real-time analytics database used in production, at scale, by companies like Uber, LinkedIn and Cisco, and which serves as the beating heart of StarTree Cloud. Here’s what’s new:
Multistage query engine improvements (for query-time JOINs)
Upsert improvements
Minion improvements
JSON index improvements
Query Editor UI improvements
Let’s dive into each of these areas of improvement, because each includes multiple elements.
Multistage Query Engine Improvements
Apache Pinot’s multistage query engine (sometimes referred to as the “v2” engine) was added in Apache Pinot 1.0, enabling performant query-time JOINs and window functions. In Apache Pinot 1.2, more features have been added to take advantage of this fundamental infrastructure.
Apache Pinot 1.2.0 introduces powerful window functions that enable more sophisticated analytics and data exploration:
LEAD: This function allows you to access values from subsequent rows within the same result set, which is useful for comparing current data with future values.
LAG: Similar to LEAD, the LAG function lets you access values from previous rows in the result set. It’s commonly used for comparing current data with past values.
FIRST_VALUE and LAST_VALUE: These functions return the first and last value in a given frame of data, respectively. They are particularly helpful for identifying trends and endpoints within a data sequence.
These window functions provide more analytical capabilities, enabling users to perform complex calculations such as trend analysis, running totals, and moving averages directly within Pinot.
Support for WITHIN GROUP clause
Improved multi-value and array function support
Improvements to scalars, transform functions, and literal handling
Improved metrics
A notable addition in Pinot 1.2.0 is the support for a “database” construct in the V2 multi-stage query engine. This feature introduces logical database support, enabling table namespace isolation within the same Pinot cluster. It significantly improves the user experience when multiple users or teams are using the same Pinot cluster by allowing:
Table Namespace Isolation: Tables can be grouped under different logical databases, preventing naming conflicts and ensuring organized data management.
Access Control: Access control policies can now be set at the database level, providing finer-grained security and better data governance.
Database Selection in Queries: Users can easily switch between different logical databases using the SET statement, such as SET database=my_db;, making it convenient to manage and query data across multiple databases.
This addition enhances the flexibility and usability of Pinot, particularly in multi-tenant environments where data separation and security are paramount.
Upsert Improvements
Upserts are one of the key “must have” features that drive users to adopt Apache Pinot. With Apache Pinot 1.2 they are even better.
Upsert Compaction Improvements
Upserts create many updates to the same record. Because Apache Pinot uses an immutable storage format for segments, to delete the old, obsolete records requires a background compaction process. Scheduling compactions is now based on the quantity of invalidDocs present. This prioritizes compactions for tables with the most invalid entries.Consistent Table View for Upsert Tables
The introduction of different consistency modes allows for tailored consistency guarantees depending on the use case (see PR#12976). Consistency is at a table partition level, which can contain many segments. The new UpsertConfig includes a consistencyMode setting with the following options:NONE: Offers no consistency guarantee and is suitable for use cases where data freshness is not critical.
SYNC: Optimized for data freshness, this mode may increase query latency and is best for low-query-per-second (QPS) scenarios. It ensures that the ingestion threads take a write lock (WLock) when updating validDocID bitmaps.
SNAPSHOT: Ideal for high-QPS and high-ingestion scenarios, this mode takes a snapshot of validDocID, refreshed periodically. The snapshot’s tolerance level can be adjusted using the upsertViewFreshnessMs query option, balancing between freshness and query performance.
Pluggable partial upsert merger
Pinot now supports customizable partial upsert mergers (see PR#11983), allowing users to define how new and existing records should be merged. This flexibility enables complex transformations, where a column’s value in the new row can be an arbitrary function of both the old and the new rows. This feature is particularly useful for applications needing custom logic to determine the final ingested record.
Upload externally-partitioned segments for upsert backfill
With this enhancement, Pinot now allows explicit specification of Kafka partitions for externally partitioned segments during upsert backfill (see PR#13107). This is particularly useful for scenarios where backfilled data is partitioned using an arbitrary hash function on a primary key. It ensures that segments are accurately assigned to their respective Kafka partitions, maintaining data consistency and integrity.
Minion Improvements
A series of improvements provide more fine-grained control over minion resources in general. In 1.2 there is now support for resource isolation based on a minionInstanceTag so you can better control the resources dedicated to compaction processes across any number of tasks and tables. Minions are also now more secure, using their own TLS port.
JSON Index Enhancements
The 1.2.0 release introduces several enhancements to the JSON index, significantly expanding its functionality and use cases:
Regex and Range Predicate Support: The JSON Index can now be used to evaluate Regex and Range predicates. This allows for more complex filtering and querying of JSON data, making it easier to search for patterns or values within JSON fields.
Contextual Array Filters: The jsonExtractIndex now supports contextual array filters, providing more precise filtering options within arrays stored in JSON documents.
Enhanced Predicate Support: JSON column types now support standard filter predicates such as =, !=, IN, and NOT IN. This enhancement is particularly convenient for scenarios where JSON values are small and need to be matched or excluded based on specific conditions.
Correct Handling of Exclusive Predicates: The JSON_MATCH function now correctly supports exclusive predicates. For instance, you can use predicates like JSON_MATCH(person, '"$.addresses[*].country" != ''us''') to find all records where at least one address is not in the US.
Multi-Value JSON Field Extraction: The jsonExtractIndex now supports extracting multi-value JSON fields and allows providing a default value when the key does not exist. This flexibility simplifies handling diverse JSON structures in data.
New isJson UDF: A new user-defined function (UDF), isJson, has been added to identify and filter out invalid JSONs during data ingestion and querying. This function enhances data quality by allowing the exclusion of malformed JSON entries.
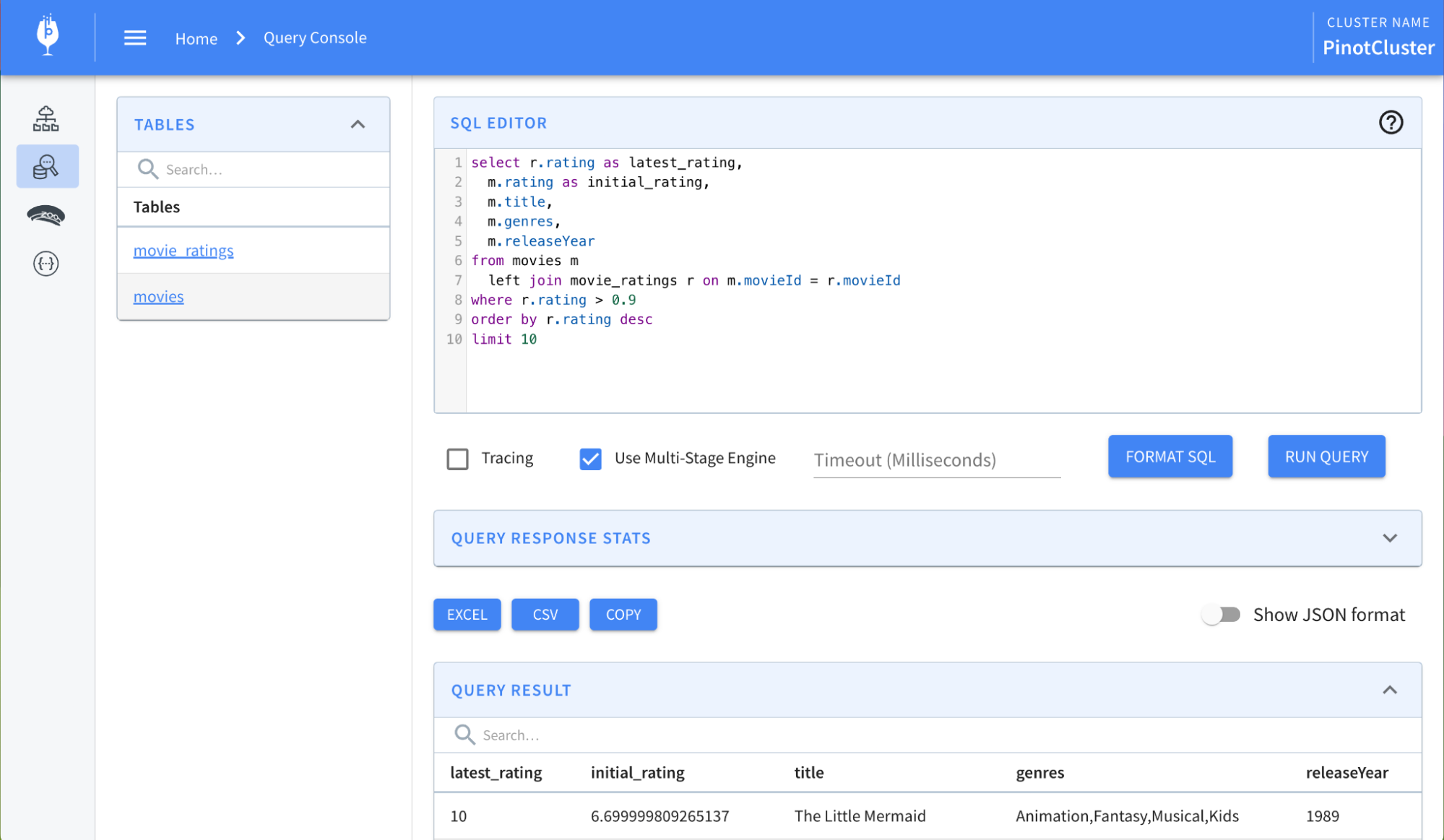
Query Editor UI Enhancements
SQL Formatting in Query Editor: You can now prettify SQL queries directly in the Controller UI. This new feature automatically formats your SQL statements, making them easier to read and edit.
Thank You to the Pinot Open Source Community
A big thank you to our community for their continued support! This release includes numerous bug fixes and performance optimizations, enhancing the stability and efficiency of Pinot. Since the last release, there were over 400 commits from nearly three dozen active open source contributors. This invaluable work is the basis for the ongoing development and improvement of the platform.
Most of all thanks to Uber’s Ankit Sultana, an active community member and committer within the community, who managed the release process. You can hear more directly from Ankit about how Uber takes advantage of Apache Pinot in this video from a meetup in San Francisco from last year.
Industry InsightsStarTree Cloud
Community Newsletter



