Stripe’s Journey to $18.6B of Transactions During Black Friday-Cyber Monday with Apache Pinot

Summary
Stripe uses Apache Pinot to power user-facing applications (Stripe user dashboards, billing analytics, Sigma reports, developer analytics) and internal use cases (failure alerts for payment processors, financial data reporting, admin tools for monitoring risk, security tools for monitoring access logs).
Stripe used Pinot to power their real-time transactional dashboard for Black Friday - Cyber Monday, which tracked 300 million+ transactions (amounting to >$18.6 billion)
Stripe uses Apache Pinot to support 10,000 queries per second
Stripe has ~8 Pinot clusters in production (largest has 3 petabytes of data)
Stripe meets stringent SLCs with Apache Pinot, including p99 query latency of 70 milliseconds and p99 ingestion lag of 30 seconds
Introduction
Stripe provides a payments infrastructure that processes more than 250 million API requests per day, with a peak of 13,000 requests per second. Stripe’s users require access to fast, fresh, and accurate data to help them review their transactions and make informed business decisions. They rely on Apache Pinot, a real-time Online Analytical Processing (OLAP) database, to deliver real-time analytics that support user-facing applications and internal use cases.
In this blog, we cover Stripe’s journey with Apache Pinot: their internal and external use cases, which teams are using Pinot, the role Pinot played within Stripe’s specialized dashboard for Black Friday - Cyber Monday, their transition to centrally managed Pinot clusters, and how they’re scaling Pinot for future needs. This blog is based on previous content produced for StarTree events in conjunction with the Stripe team, as well as a press release published by Stripe. All references are linked throughout.
Apache Pinot powers Stripe’s user-facing applications
Stripe uses Apache Pinot to power a number of their external, user-facing applications. These include:
Stripe user dashboards
Billing analytics
Sigma reports
Developer analytics
For example, several of the widgets and charts that a user sees in their home dashboard upon logging into Stripe run via Pinot. This includes the payment widget, which dives into payment details to help a user track their business’s financial health.

Stripe also uses Apache Pinot for API analytics. For those who use Stripe APIs, all metrics about API requests and API errors run via Pinot.
How Stripe’s internal teams use Pinot
Internally, Stripe’s teams also leverage Pinot for several different use cases, including:
Failure alerts for payment processors: Stripe’s product teams use Pinot to monitor and deliver alerts when a payment processor fails, signaling the platform to direct users to another payment processor.
Financial data reporting: Their financial data reporting team uses Pinot to analyze Stripe’s transaction data and internal financial health.
Admin tools to monitor risk: Stripe’s teams have access to risk analytics via Pinot.
Security tools to monitor access logs: With Pinot, Stripe is able to track access logs and ensure there are no security breaches in their internal services and systems.
Ingesting financial data in real-time
Stripe’s data streaming and real-time analytics pipeline includes several open source technologies. Stripe uses a combination of Apache Flink for stream processing, Apache Kafka for fast data streaming, and Apache Pinot for real-time analytics.

Stripe’s Pinot setup
Today, Stripe has about 8 Pinot clusters in production, the largest of which has 3 petabytes of data. Their Pinot clusters support a maximum of 10,000 queries per second (QPS). Stripe runs approximately 120 tables in production, many of which are hybrid tables with both real-time and offline data.

Pinot supports several of Stripe’s most latency-sensitive use cases, and must maintain stringent Service-Level Commitments (SLCs). With Pinot, Stripe is able to meet their SLCs of:
p99 query latency of 70 milliseconds
p99 ingestion lag of 30 seconds
99.99% availability

Stripe’s journey with Pinot
Stripe started their journey with Apache Pinot in 2021, when their financial team and reporting data team ran separate proofs of concept (POCs) to see if Pinot would meet their real-time data needs. The financial team adopted Pinot to build a query/search feature for transaction data, and the reporting data team adopted Pinot for a user-facing analytics application.
In 2022, another Stripe team — the stream analytics team — started migrating their legacy time-series aggregation system to Pinot, which they use to power user-facing dashboards.

Supporting $18.6B transactions for Black Friday - Cyber Monday
In 2023, Stripe used Apache Pinot to power their real-time transactional dashboard for the Black Friday - Cyber Monday (BFCM) holiday weekend. Stripe’s BFCM dashboard tracked the 300 million-plus transactions that occurred during the four-day period, amounting to a transaction volume of more than $18.6 billion.
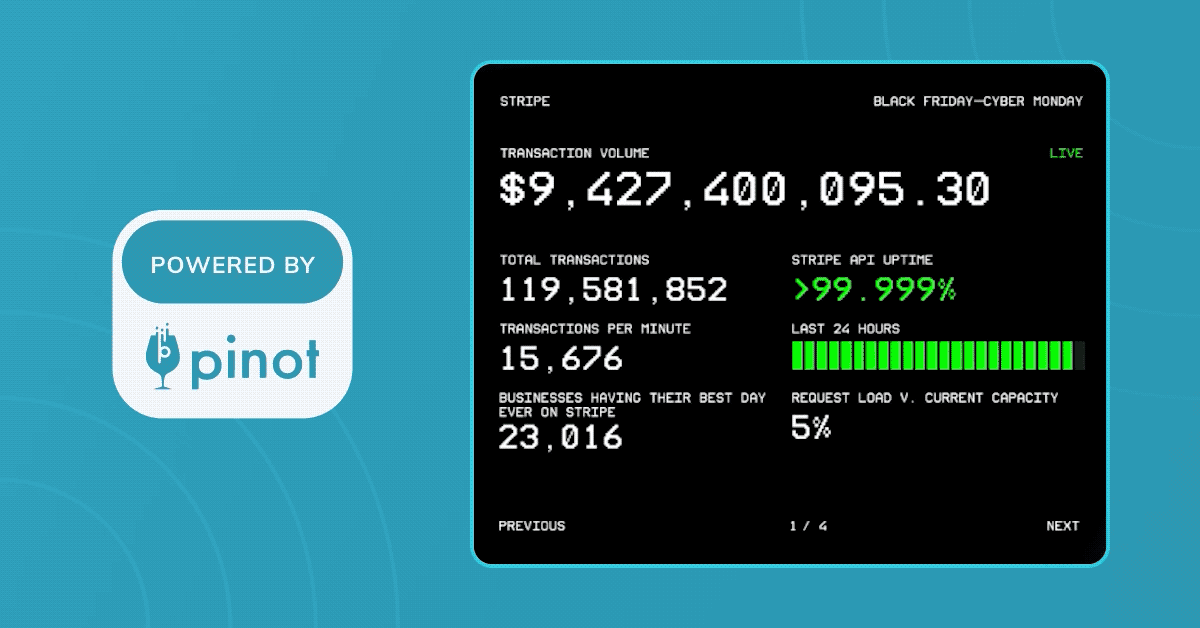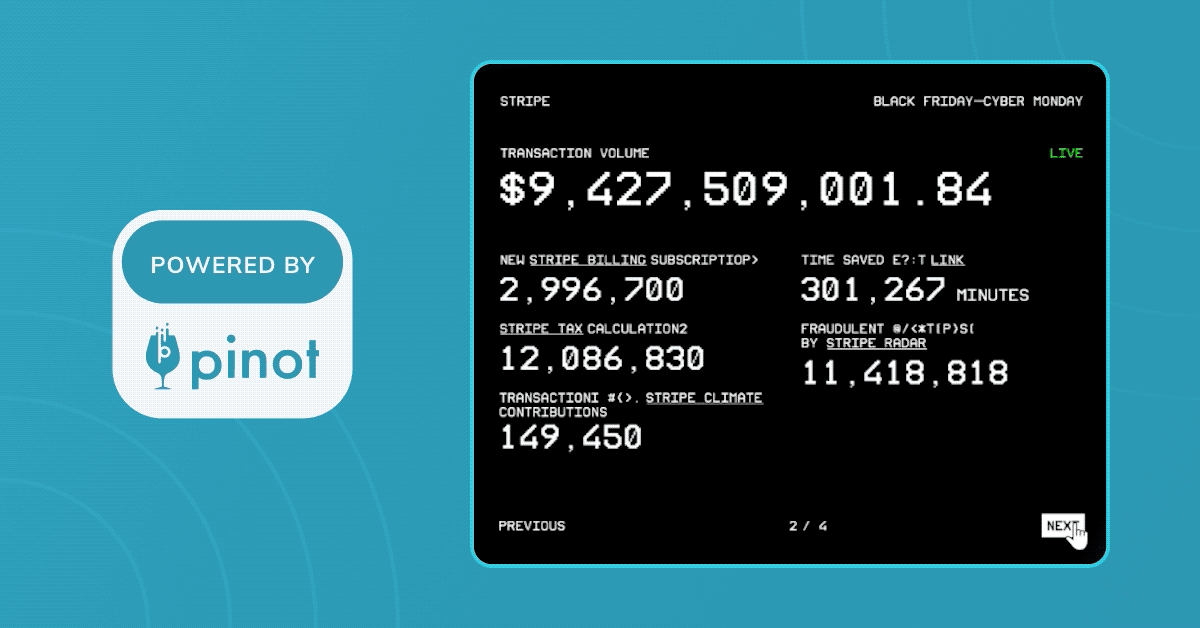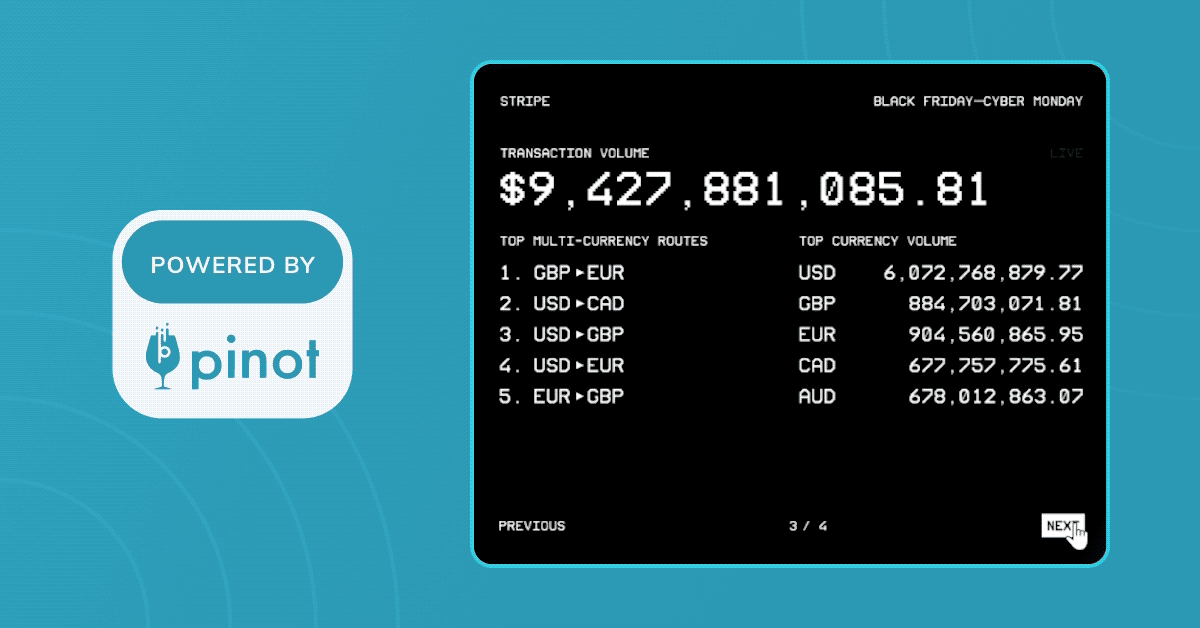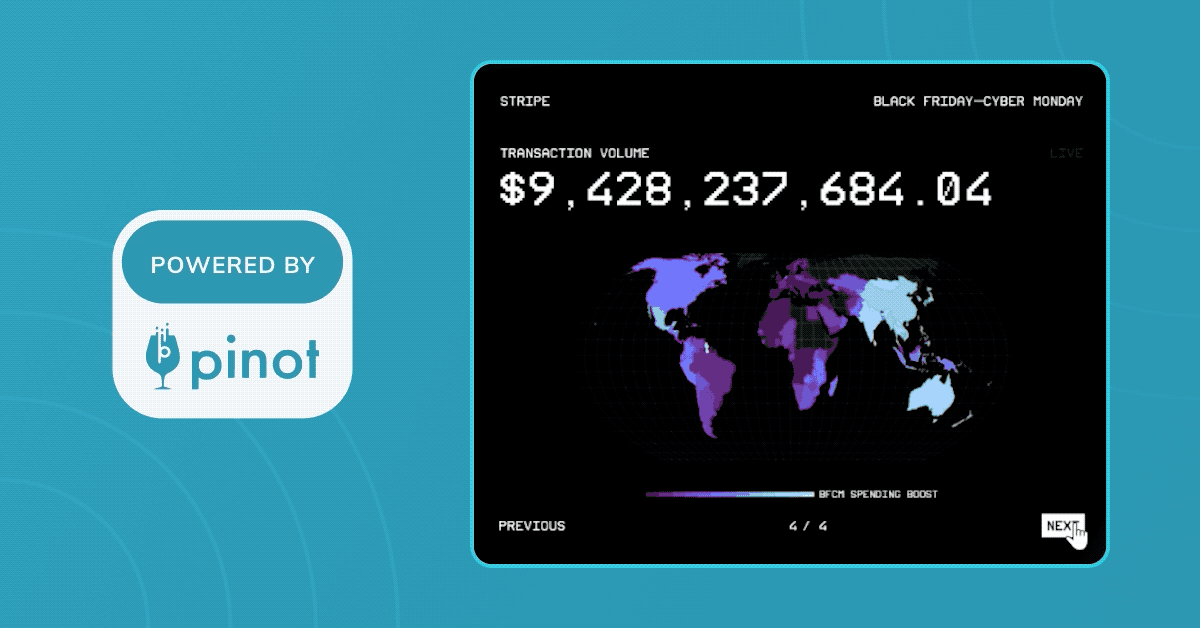
Prime Day: Brought to you by Stripe and Pinot, powered by AWS
To support massive workloads like BFCM and Prime Day at high speed and scale, Stripe relies on AWS EC2 instances for thousands of fast processors (vCPUs) and hundreds of terabytes fast NVMe SSDs. Stripe’s relationship with AWS goes back to 2011, when it first began to offer PCI-compliant payment systems entirely on AWS. This deep relationship works both ways: in 2023 Stripe and AWS signed an expanded global agreement, with Stripe becoming a strategic payments partner for Amazon in the US, Europe, and Canada. So the next time you check out on Prime Day, or purchase anything through Amazon Prime, Audible, Kindle, or Amazon Pay, consider that Stripe, powered by Apache Pinot, is likely at the heart of your purchase.
Use case deep dive: Migrating their legacy time-series aggregation system to Pinot
Stripe has a time-series aggregation system that aggregates real-time and offline data for dozens of merchant-facing dashboard charts. Previously the team used disparate systems and experienced several severe incidents due to over-aggregated results (from how their real-time ingestion flow was set up). The team selected Pinot in part because of its exactly once ingestion, the ability to support their latency SLC, and its SQL interface for querying data.
With Pinot, the time-series aggregation system ingests 150,000 events per second with 20,000 QPS at 99.99% availability. All SLCs are being met, and some SLCs are even performing better compared to their previous setup. Their latency metrics are as follows:
| p50 | 4 ms |
| p95 | 7 ms |
| p99 | 21 ms |
| p99.9 | 63 ms |
Learn more about how Stripe migrated their time-series aggregation system to Pinot from Johan Adami (Software Engineer, Stripe) in his 2022 RealTime Analytics Summit talk, Migrating Low-Latency Time-Series Aggregation System to Pinot.
Improving the Pinot experience for internal users
As several teams began adopting Pinot for separate projects, Stripe needed a better method for oversight and process alignment. Today the stream analytics team owns and manages all Pinot clusters, delivering a unified user experience to all Stripe projects and applications that are run on Pinot.
Previously, the process for starting a project on Pinot happened at the team level, often happening in a silo. Today, any internal user interested in Pinot starts by sharing their use case with the stream analytics (SA) team. The SA team will ensure Pinot is the right tool by collecting use case needs pertaining to QPS, latency, storage, freshness, and an example query (if relevant).
Next, the SA team helps the internal user determine whether to use an existing Pinot cluster or if a new cluster is needed. They evaluate the use case against the current Pinot cluster setups for Stripe’s platform-like offerings, considering dimensions such as:
Types of queries supported
Data aggregation interface
Types of data supported
Data freshness and latency requirements
|
|
Time-Series Aggregation Platform |
Reporting Data Platform |
New Pinot cluster |
Types of queries
|
Predefined SQL queries | Predefined SQL queries | Unique query requirements |
Data aggregation
|
Predefined interfaces for aggregating data | Predefined interfaces for aggregating data | Unique data aggregation (or lack thereof) requirements |
Types of data
|
Real-time / offline / hybrid | Offline tables | Real-time / offline / hybrid |
Data freshness
|
p99: 30 seconds | 0 (hours) | Unique freshness requirements |
Data latency
|
p99: 75 ms | p99: 200 ms | Unique latency requirements |
Once the Pinot cluster is selected, the SA team works with the internal user to ingest data (whether real-time, offline, or hybrid) and move the use case to production. The chart below outlines the steps taken to ingest data and finish setting up the tables or cluster:
| Real-time data | Offline data | Resource creation |
|
|
|
Finally, The SA team oversees the testing and rollout of new Pinot use cases, monitors observability, and ensures SLAs (freshness, availability, latency) are met.
Hear more about Stripe’s experience building a scalable process and infrastructure using Pinot from Lakshmi Rao (Software Engineer, Stripe).
The future state of Apache Pinot at Stripe
Now that Stripe has unified cluster management and built out an internal process for adding new use cases, the next goal for the SA team is to automate more of the process. In particular, the team is looking to improve the user experience by:
Automating the user onboarding workflow
Improving ease of use by building a unified query API
Automating table and tenant creation
Automating operations such as scaling clusters up/down
Hear more from Stripe at Real-Time Analytics Summit 2024
Now that Stripe is a few years into their Pinot journey, hear about the operational lessons they’ve learned along the way. Software Engineer David Yang will be speaking at Real-Time Analytics Summit 2024, taking place May 8-9, 2024 in San Jose, California. Read more about David’s talk, Operating Apache Pinot at Scale, and see the full Summit agenda.
REGISTER NOW FOR RTA SUMMIT 2024
Join the growing list of organizations seeing success with Pinot
Stripe is far from alone in its use of Apache Pinot. Uber saved more than $2 million annually on infrastructure costs by migrating to Apache Pinot. Cisco Webex found that Apache Pinot provided 5x to 150x lower latencies than their previous platform, Elasticsearch.
Interested in trying out Pinot for yourself? Access fully managed Apache Pinot and a hassle-free setup with our free trial of StarTree Cloud.
Use Case
Community Newsletter



